Buffer Overflows
A bujfer overflow is a weakness in code where the bounds of an array (often a buffer) can be exceeded. An attacker who is able to write into the buffer, directly or indirectly, will be able to write over other data in memory and cause the code to do something it wasn't supposed to.
Generally, this means that an attacker could coerce a program into executing arbitrary code of the attacker's choice. Often the attacker's goal is to have this "arbitrary code" start a user shell, preferably with all the privileges of the subverted program - for this reason, the code the attacker tries to have run is generically referred to as shellcode.
One question immediately arises: why are these buffers' array bounds not checked?
Some languages, like C, don't have automatic bounds checking. Sometimes, bounds-checking code is present, but has bugs. Other times, a buffer overflow is an indirect effect of another bug. Buffer overflows are not new. The general principle was known at least as far back as 1972, and a buffer overflow was exploited by the Internet worm in 1988.
Stack Smashing
Stack smashing is a specific type of buffer overflow, where the buffer being overflowed is located in the stack. In other words, the buffer is a local variable in the code, as shown below.
def main(): fill_buffer()
def fill_buffer() : character buffer[100] i = 0 ch = input () while ch 9 NEWLINE: buffer = ch ch = input() i = i + 1
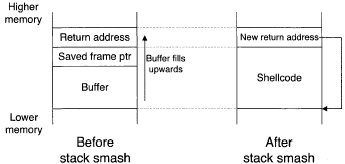
Here, no bounds checking is done on the input being read. As the stack-allocated buffer is filled from low to high memory, an attacker can continue writing, right over top of the return address on the stack.
The attacker's input can be shellcode, followed by the address of the shellcode on the stack - when f ill_buf f er returns, it resumes execution where the attacker specified, and runs the shellcode. This is illustrated in Figure 6.6. The main problem for the attacker is finding out the address of the buffer in the stack.
Fortunately for the attacker, many operating systems situate a process' stack at the same memory location each time a program runs. To account for slight variance, an attacker can precede the shellcode with a sequence of "NOP" instructions that do nothing."
Because jumping anyplace into this NOP sequence will cause execution to slide into the shellcode, this is called a NOP sled. The exploit string, the input sent by the attacker, is thus
NOP NOP NOP ... shellcode new-return-address
The space taken up by the NOP sled and the shellcode must be equal to the distance from the start of the buffer to the return address on the stack, otherwise the new return address won't be written to the correct spot on the stack.
The saved frame pointer on the stack doesn't have to be preserved, either, because execution won't be returning to the caller anyway. There are several other issues that arise for an attacker:
- The length of the exploit string must be known, but the exact location on the stack may not be, due to the NOP sled. The addresses of strings in the shellcode cannot be hardcoded as a result - for example, shellcode may need a string containing the path to a user shell like /bin/sh.
Some architectures allow addresses to be specified relative to the program counter's value, called PC-relative addressing. Other architectures, like the Intel x86, don't have PC-relative addressing, but do allow PC-relative subroutine calls.
On the x86, a PC-relative jump from one part of the shellcode to another part of the shellcode will leave the caller's location on top of the stack. This location is the stack address of the shellcode.
- Depending on the code being attacked, some byte values can terminate the input before the buffer is overflowed. In code above, for instance, a newline character terminates the input. The exploit string cannot contain these input-terminating values.
An attacker must rewrite their exploit string if necessary, to compute the forbidden values instead of containing them directly. For example, an ASCII NUL character (byte value 0) can be computed by XORing a value with itself.
- A buffer may be too small to hold the shellcode. One possible workaround is to write the shellcode after writing the new return address. Another possibility is to use the program's environment.
Most operating systems allow environment variables to be set, which are variable names and values that are copied into a program's address space when it starts running. If an attacker controls the exploited program's environment, they can put their shellcode into an environment variable.
Instead of making the new return address point to the overwritten buffer, the attacker points the new return address to the environment variable's memory location.
Frame Pointer Overwriting
What if a buffer can be overrun by only one byte? Can an attack be staged?
Under some circumstances, it can, except instead of overwriting the return address on the stack, the attack overwrites a byte of the saved frame pointer. This is frame pointer overwriting attack. The success of this attack relies on two factors:
- Some architectures demand that data be aligned in memory, meaning that the data must start at a specific byte boundary. For example, integers may be required to be aligned to a four-byte boundary, where the last two bits of the data's memory address are zero.
When necessary, compilers will insert padding - unused bytes - to ensure that alignment constraints are met. There must be no padding on the stack between the buffer and the saved frame pointer for a frame pointer overwrite to work.
Otherwise, writing one byte beyond the buffer would only alter a padding byte, not the saved frame pointer. Padding aside, no other data items can reside between the buffer and saved frame pointer, for similar reasons.
- The architecture must be little-endian. Endianness refers to the way an architecture stores data in memory. For example, consider the four-byte hexadecimal number aabbccdd. A big-endian machine would store the most significant byte first in memory; a little-endian machine like the Intel x86 would store the least significant byte first.
On a big-endian machine, a frame pointer overwrite would change the most significant byte of the saved frame pointer; this would radically change where the saved frame pointer points in memory.
However, on a littleendian machine, the overwrite changes the least significant byte, causing the saved frame pointer to only change slightly.
When the called subroutine returns, it restores the saved frame pointer from the stack; the caller's code will then use that frame pointer value. After a frame pointer attack, the caller will have a distorted view of where its stack frame is.
For example, the code in Figure above allows one byte to be written beyond the buffer, because it erroneously uses <= instead of <. Figure 2 shows the stack layout before and after the attack.
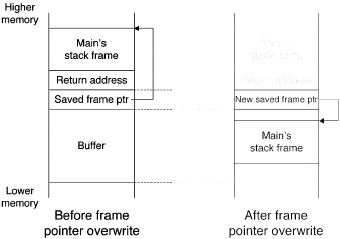
By overwriting the buffer and changing the saved frame pointer, the attacker can make the saved frame pointer point inside the buffer, something the attacker controls. The attacker can then forge a stack frame for the caller, convincing the caller's code to use fake stack frame values, and eventually return to a return address of the attacker's choice.
The exploit string would be:
NOP NOP NOP ... shellcode fake-stack-frame fake-saved-frame-pointer shellcode-address new-frame-pointer-byte
A saved frame pointer attack isn't straightforward to mount, but serves to demonstrate two things. First, an off-by-one error is enough to leave an exploitable weakness. Second, it demonstrates that just guarding the return address on the stack is insufficient as a defense.
Returns into Libraries
The success of basic stack smashing attacks relies on the shellcode they inject into the stack-allocated buffer. One suggested defense against these attacks is to make the stack's memory nonexecutable. In other words, the CPU would be unable to execute code in the stack, even if specifically directed to do so.
Unfortunately, this defense doesn't work. If an attacker can't run arbitrary code, they can still run other code. As it happens, there is a huge repository of interesting code already loaded into the address space of most processes: shared library code.
An attacker can overwrite a return address on the stack to point to a shared library routine to execute. For example, an attacker may call the system library routine, which runs an arbitrary command.
Arguments may be passed to library routines by the attacker by writing beyond the return address in the stack. Figure 3 shows the initial stack contents a subroutine would expect to see when called with arguments;
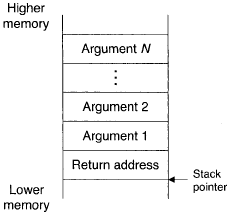
Figure 4 shows a retum-to-library attack which passes arguments.
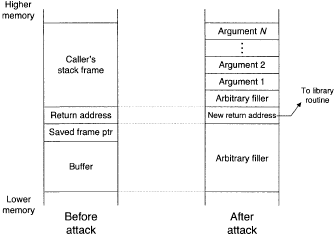
Notice the extra placeholder required, because the called library function expects a return address on the stack at that location. This attack is often called a return-to-libc attack, because the C shared library is the usual target, but the attack's concept is generalizable to any shared library.
Heap Overflows
This next attack is somewhat of a misnomer. A heap overflow is a buffer overflow, where the buffer is located in the heap or the data segment. The idea is not to overwrite the return address or the saved frame pointer, but to overwrite other variables that are adjacent to the buffer.
These are more "portable" in a sense, because heap overflows don't rely on assumptions about stack layout, byte ordering, or calling conventions. For example, the following global declarations would be allocated to the data segment:
character buffer[123] function pointer p
Overflowing the buffer allows an attacker to change the value of the function pointer p, which is the address of a function to call. If the program performs a function call using p later, then it jumps to the address the attacker specified; again, this allows an attacker to run arbitrary code.
The range of possibilities for heap overflow attacks depends on the variables that can be overwritten, how the program uses those variables, and the imagination of the attacker.
Memory Allocator Attacks
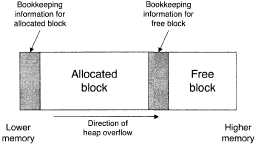
One way heap overflows can be used is to attack the dynamic memory allocator. As previously mentioned, space is dynamically allocated from the heap. The allocator needs to maintain bookkeeping information for each block of memory that it oversees in the heap, allocated or unallocated.
Allocators find space for this information by overallocating memory - when a program requests an X-byte block of memory, the allocator reserves extra space:
- Before the block, room for bookkeeping information.
- After the block, space may be needed to round the block size up. This may be done to avoid fragmenting the heap with remainder blocks that are too small to be useful, or to observe memory alignment constraints.
The key observation is that the bookkeeping information is stored in the heap, following an allocated block. Exploiting a heap overflow in one block allows the bookkeeping information for the following block to be overwritten, as shown in Figure 5.
By itself, this isn't terribly interesting, but memory allocators tend to keep track of free, unallocated memory blocks in a data structure called difree list. As in Figure 6, the free list will be assumed here to be a doubly-linked list, so that blocks can be removed from the list easily.
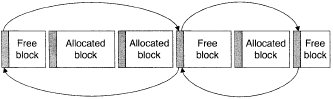
When an allocated block is freed, the allocator checks to see if the block immediately following it is also free; if so, the two can be merged to make one larger block of free memory. This is where the free list is used: the already-free block must be unlinked from the free list, in favor of the merged block.
A typical sequence for unlinking a block from a doubly-linked list is shown in Figure 7.
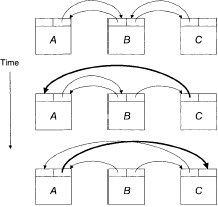
The blocks on the list have been abstracted into uniform list nodes, each with two pointers as bookkeeping information, a "previous" pointer pointing to the previous list node, and a "next" pointer pointing to the next node. From the initial state, there are two steps to unlink a node B:
- The next node, C, is found by following B's next pointer. C's previous pointer is set to the value of B's previous pointer.
- B's previous pointer is followed to find the previous node, A, A's next pointer is set to the value of B's next pointer.
Now, say that an attacker exploits a heap overflow in the allocated block immediately before fi, and overwrites B\ list pointers. B's previous pointer is set to the address of the attacker's shellcode, and fi's next pointer is assigned the address of a code pointer that already exists in the program.
For example, this code pointer may be a return address on the stack, or a function pointer in the data segment. The attacker then waits for the program to free the memory block it overflowed. Figure 8 illustrates the result.
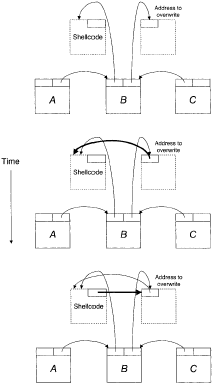
The memory allocator finds the next adjacent block {E) free, and tries to merge it. When the allocator unlinks B from the list, it erroneously assumes that B's two pointers point to free list nodes.
Following the same two steps as above, the allocator overwrites the targeted code pointer with the shellcode's address in the first step. This was the primary goal of the exploit.
The second step writes a pointer just past the start of the shellcode. This would normally render the shellcode unrunnable, but the shellcode can be made to start with a jump instruction, skipping over the part of the shellcode that is overwritten during unlinking.
After the allocator's unlinking is complete, the targeted code address points to the shellcode, and the shellcode is run whenever the program uses that overwritten code address.
Integer Overflows
In most programming languages, numbers do not have infinite precision. For instance, the range of integers may be limited to what can be encoded in 16 bits This leads to some interesting effects:
- Integer overflows, where a value "wraps around." For example, 30000 + 30000 = -5536.
- Sign errors. Mixing signed and unsigned numbers can lead to unexpected results. The unsigned value 65432 is -104 when stored in a signed variable, for instance.
- Truncation errors, when a higher-precision value is stored in a variable with lower precision. For example, the 32-bit value 8675309 becomes 24557 in 16 bits.
Few languages check for these kinds of problems, because doing so would occasionally impose additional overhead, and more occasionally, the programmer actually intended for the effect to occur.
At this point, it should come as little surprise that these effects can be exploited by an attacker - they are collectively called integer overflow attacks. Usually the attack isn't direct, but uses an integer overflow to cause other types of weaknesses, like buffer overflows.
The code above has such a problem, and is derived from real code. All numbers are 16 bits long: n is the number of elements in an array to be read in; size is the size in bytes of each array element; total size is the total number of bytes required to hold the array.
If an attacker's input results in n being 1234 and size being 56, their product is 69104, which doesn't fit in 16 bits - total size is set to 3568 instead. As a result of the integer overflow, only 3568 bytes of dynamic memory are allocated, yet the attacker can feed in 69104 bytes of input in the loop that follows, giving a heap overflow.

