Security Weaknesses Exploited
Weaknesses are thin ice on the frozen lake of security, vulnerable points through which a system's security may be compromised. Thin ice doesn't always break, and not all weaknesses are exploitable. However, an examination of the devious and ingenious ways that security can be breached is enlightening.
Malware may exploit weaknesses to initially infiltrate a system, or to gain additional privileges on an already-compromised machine. The weaknesses may be exploited automatically by malware authors' creations, or manually by people directly targeting a system.
The initiator of an exploit attempt will be generically called an "attacker." Weaknesses fall into two broad categories, based on where the weakness lies. Technical weaknesses involve tricking the target computer, while human weaknesses involve tricking people.
Technical Weaknesses
Weaknesses in hardware are possible, but weaknesses in software are disturbingly common. After some background material, a number of frequent weaknesses are discussed, such as various kinds of buffer overflow (stack smashing, frame pointer overwriting, returns into libraries, heap overflows, and memory allocator attacks), integer overflows, and format string vulnerabilities.
This is unfortunately not an exhaustive list of all possible weaknesses. At the end of this section, how weaknesses are found, and defenses to these weaknesses are examined. Where possible, weaknesses and defenses are presented in a language- and architecture-independent way.
Conceptually, a process' address space is divided into four "segments":
- The program's code resides in the fixed-size code segment. This segment is usually read-only.
- Program data whose sizes are known at compile-time are in the fixed-size data segment.
- A "heap" segment follows the data segment and grows upwards; it also holds program data. The heap as used in this context has nothing whatsoever to do with a heap data structure, even though they share the name.
- A stack starts at high memory and grows downwards. In practice, the direction of stack growth depends on the architecture. Downwards growth will be assumed here for concreteness.
A variable in an imperative language, like C, C++, and Java, is allocated to a segment based on the variable's lifetime and the persistence of its data. A sample C program with different types of variable allocation is shown in Figure 1.
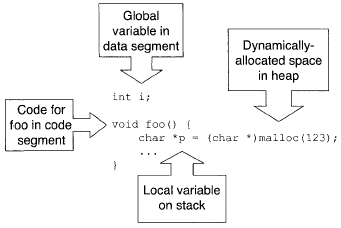
Global variables have known sizes and persist throughout run-time, so they are placed into the data segment by a compiler. Space for dynamic allocation has to grow on demand; dynamic allocation is done from the heap segment.
Finally, local variables don't persist beyond the return of a subroutine, and subroutine calls within a program follow a stack discipline, so local variables are allocated space on the stack. A subroutine gets a new copy of its local variables each time the subroutine is called.
These are stored in the subroutine's stack frame, which can be thought of as a structure on the stack. When a subroutine is entered, space for the subroutine's stack frame is allocated on the stack; when a subroutine exits, its stack frame space is deallocated. The code to manage the stack frame is added automatically by a compiler.
Figure 2 shows how the stack frames change when code runs.
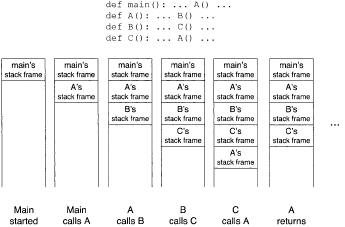
Note that A is called a second time before the first call to A has returned, and consequently A has two stack frames on the stack at that point, one for each invocation. More than local variables may be found in a stack frame. It serves as a repository for all manner of bookkeeping information, depending on the particular subroutine, including:
- Saved register values. Registers are a limited resource, and it is often the case that multiple subroutines will use the same registers.
Calling conventions specify the protocol for saving, and thus preserving, register contents that are not supposed to be changed - this may be done by the calling subroutine (the caller), the called subroutine (the callee), or some combination of the two. If registers need to be saved, they will be saved into the stack frame.
- Temporary space. There may not be enough registers to hold all necessary values that a subroutine needs, and some values may be placed in temporary space in the stack frame.
- Input arguments to the subroutine. Arguments passed to the subroutine, if any.
- Output arguments from the subroutine. These are arguments that the subroutine passes to other subroutines that it calls.
- Return address. When the subroutine returns, this is the address at which execution resumes.
- Saved frame pointer. A register is usually reserved for use as a stack pointer, but the stack pointer may move about as arguments and other data are pushed onto the stack.
A suhroutinQ's frame pointer is a register that always points to a fixed position within the subroutine's stack frame, so that a subroutine can always locate its local variables with constant offsets.
Because each newly-called subroutine will have its own stack frame, and thus its own frame pointer, the previous value of the frame pointer must be saved in the stack frame.
The inclusion of the last four as part of the stack frame proper is philosophical; some architectures include them, some don't. They will be assumed to be separate here in order to illustrate software weaknesses.
For similar reasons, similar assumptions: arguments are passed on the stack, the return address and saved frame pointer are on the stack. Variations of the weaknesses described here can often be found for situations where these assumptions aren't true. Figure 3 shows the stack before and after a subroutine call.

Prior to the call, the caller will have placed any arguments being passed into its argument build area. The call instruction will push the return address onto the stack and transfer execution to the callee. The callee's code will begin by saving the old frame pointer onto the stack and creating a new stack frame.

