Computer Worm Propagation
Humans are slow, compared to computers and computer networks. Worms thus have the potential to spread very, very quickly, because humans don't have to be involved in the process of worm propagation. At the extreme end of the scale are fast burners, worms that propagate as fast as they possibly can.
Some of these worms have special names, reflecting their speed. A Warhol worm infects its vulnerable population in less than 15 minutes; this name comes from artist Andy Warhol's famous quote 'In the future everyone will be famous for fifteen minutes.'
A flash worm goes one better, and infects the vulnerable population in a matter of seconds. How can a worm propagate this quickly?
With a combination of these methods:
- Shorten the initial startup time.
- Minimize contention between instances of the worm. This includes avoiding general contention in network traffic, as well as avoiding pointless attempts to re-infect the same machine.
- Increase the rate at which potential target machines are probed, by scanning them in parallel. This is a tradeoff, because such network activity can result in network traffic contention.
- Attack using low-overhead network protocols. The less back-and-forth that a network protocol requires, the faster a worm using that protocol can spread. The Slammer worm, for example, used the User Datagram Protocol (UDP) to infect SQL database servers using a buffer overflow.
UDP is a lightweight, connectionless protocol: there is no overhead involved to set up a logical network connection between two computers trying to communicate. From Slammer's point of view, this meant one network packet, one new victim.
In contrast, worms using a connection-based network protocol like the Transmission Control Protocol (TCP) have several packets' worth of overhead to establish a connection, before any exploit can even be started.
Initial Seeding
Worms need to be injected into a network somehow. The way that a worm is initially released is called seeding, A single network entry point would be relatively easy to trace back to the worm author, and start the worm's growth curve at its lowest point.
An effective seeding method should be as anonymous and untraceable as possible, and distribute many instances of the worm into the network. Three possibilities have been suggested:
- Wireless networks. There are many, many wireless networks connected to the Internet with little or no security enabled. Using wireless networks for seeding satisfies the anonymity criterion, although physical proximity to the wireless access point by the worm writer is required, making this option not entirely risk-free.
Barring a co-ordinated release, however, this method of seeding doesn't scale well to injecting large worm populations. A co-ordinated release is risky, too, as many people will know about the worm and its creator.
- Spam. Seeding a worm by spamming the worm out to people can satisfy both effectiveness criteria: anonymity and volume. Spamming can be used to seed worms even when the worm doesn't normally propagate through email.
- Botnets. Botnets may be used in several ways for seeding and, like spamming, meet both effectiveness criteria. Botnets may be used to send the worm's seeding spam, and they may be also used to release the worm directly in a highly-distributed way.
Access to common network services can be had in a hard-to-trace way, so this list is far from complete.
Finding Targets
On the Internet, a machine is identified in two ways: by a domain name and an Internet Protocol (IP) address. Domain names are a convenience for humans; they are human-readable and are quietly mapped into IP addresses.
IP addresses, which are just numbers, are used internally for the real business of networking, like routing Internet traffic from place to place. IP addresses come in two flavors, distinguished by a version number: the most prevalent kind now are version 4 addresses {IPv4), but support for version 6 addresses {IPv6) is increasing.
IPv4 addresses are shorter, only 32 bits compared to IPv6's 128 bits, and the same principles apply to both in terms of worm propagation; this book will use IPv4 addresses for conciseness. The bits of an IP address are partitioned to facilitate routing packets to the correct machine.
Part of the address describes the network, part identifies the computer (host) within that network. IP addresses are categorized based on their size:
| Network Class | Network Bits | Host Bits |
| Class A | 8 | 24 |
| Class B | 16 | 16 |
| Class C | 24 | 8 |
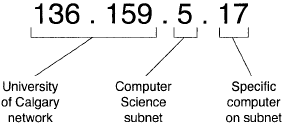
For example. Figure 1 breaks down the IP address for the web server at the University of Calgary's Department of Computer Science. The University of Calgary has a class B address, 136.159; its host part is further subdivided, to identify a subnet, 5, and the exact host on that subnet, 17.
Why is this relevant to worms?
A worm has to identify a potential target machine. For worm propagation, it is substantially easier for a worm to guess at an IP address and find a target than it is for a worm to guess correctly at a domain name.
A worm looking for machines to infect is said to scan for targets; this is different from the use of "scan" to describe anti-virus activity. There are five basic strategies that a worm can use to scan:
Random scanning
A worm may pick a target by randomly choosing a value to use as an IP address. This was done, for example, by Code Red I. Choosing an IP address randomly can select a target literally anywhere in the world.
Localized scanning
Random scanning is good for widespread distribution, but it's a hit-and-miss approach for worms exploiting technical vulnerabilities to spread. It is much likelier that computers on the same network, in the same administrative domain, are going to be maintained in a similar fashion.
For example, if one Windows machine on a network has an unpatched buffer overflow, the chances are good that another Windows machine on the same network is going to be unpatched too. Localized scanning tries to take advantage of this.
Target machines are again chosen randomly, but with a bias towards local machines; a "local machine" is heuristically selected by taking advantage of the IP address partitioning described above.
Hit-list scanning
Prior to worm release, a "hit-list" can be compiled which contains the IP addresses of some machines known to be vulnerable to a technical flaw the worm plans to exploit. Compiling such a list is a possible application for a previously-released surreptitious worm, or a botnet.
The list need not be 100% accurate, since it will only be used as a starting point, and doesn't need to contain a large number of IP addresses - 50,000 or less are enough. After its release, the worm starts by targeting the machines named in the hitlist.
Each time the worm successfully propagates, it divides the remainder of the list in half, sending half along with the new worm instance. Once the list is exhausted, the worm can fall back onto other scanning strategies. Hit-list scanning is useful for two reasons:
- Avoiding contention. The hit-list keeps multiple instances of a worm from targeting the same machines.
- Speeding up initial spread. By providing a list of known targets, slow propagation by trial-and-error is avoided, and the worm's growth curve shifts to the left as a result.
A variation on the hit-list scheme precompiles a list of all vulnerable machines on the Internet, and sends it along with the worm in compressed form.
Permutation scanning
If a worm is able to tell whether or not a target candidate is already infected, then other means of contention avoidance can be used. Permutation scanning is where instances of a worm share a common permutation of the IP address space, a pseudo-random sequence over all possible IP address values.
Each new instance is given a position in the sequence at which to start infecting, and the worm continues to work through the sequence from there. If a machine is encountered which is already infected, then the worm picks a new spot in the sequence randomly.
This gives the worm a simple mechanism for distributed coordination without any communication overhead between worm instances. (Interestingly, peer-to-peer networks for file sharing share the same need for low-overhead distributed coordination.)
This coordination mechanism can be used by the worm to heuristically detect saturation, too. If a worm instance continually finds already-infected machines, despite randomly resituating itself in the permutation sequence, then it can serve as an indicator that most of the vulnerable machines have been infected.
More generally, a worm can mathematically model its own growth curve, to estimate how close it is to the saturation point. The saturation point can signal the opportune time to release a payload, because there is little more to do in terms of spreading, and countermeasures to the worm are doubtlessly being deployed already.
Topological scanning
Information on infected machines can be used to select new targets, instead of using a random search. This is called topological scanning, because the worm follows the topology of the information it finds. The topology followed may or may not coincide with the physical network topology.
A worm may follow information about a machine's network interfaces to new target hosts, but other types of information can result in propagation along social networks. Email worms can mail themselves to email addresses they mine off an infected machine, and IM worms can send themselves to people in a victim's "buddy list.
Topological scanning is particularly useful for propagation in large, sparse address spaces. The Internet worm, for example, used topological scanning due to the relatively small number of machines in the IP address space of 1988. In contrast, random scanning would waste a lot of effort locating targets in such an address space.
Passive Scanning
A surreptitious worm can wait for topological information to come to it. A passive scanning worm can eavesdrop, or sniff, network traffic to gather information about:
- Valid IP addresses. The worm can gather the addresses of potefttial targets in a way that dodges some of the worm countermeasures.
- Operating system and services. A worm can benefit from knowing a target machine's operating system type, operating system version, network services, and network service versions. Worms able to exploit multiple technical weaknesses can pick a suitable infection vector, and other worms can rule out unsuitable targets.
- Network traffic patterns. A slow worm can limit its network activity to times when there is normally legitimate network activity. The other network activity can act as cover traffic for the worm's operation.
In some cases targets have already been identified for other reasons, and a worm need only extract the information. For example, the Santy worm exploited a flaw in web software, and used Google to search for targets.
Putting all the pieces together - virus-like concealment, exploitation of technical and human weaknesses, hijacking legitimate transactions, extremely rapid spreading - worms are a very potent type of malware. Equally potent defensive measures are needed.

