Capture and Containment Computer Worm
If defense is about keeping a worm out, then capture and containment is about keeping a worm in. This may seem like a counterintuitive thing to do, but if a worm has breached the primary defenses, then limiting the worm's spread may be the best remaining option.
It has even been suggested that it is naive to assume that all machines can remain clean during a worm attack, and that some machines may have to be sacrificed to ensure the survival of the majority. Worm containment can limit internal spread within a network. This reduces the amount of worm infections to clean up, and also has wider repercussions.
Containing a worm and preventing it from spreading to other people's networks is arguably part of being a good Internet neighbor, but more practically, reasonable containment measures may limit legal liability. Two containment measures are presented in this section, reverse firewalls and throttling.
Worm capture can be done for a variety of reasons. Capturing a worm can provide an early warning of worm activity. It can also slow and limit a worm's spread, depending on the type of worm and worm capture. Honeypots are one method of worm capture.
Honey pots
Honeypots are computers that are meant to be compromised, computers which may be either real or emulated. Early documented examples were intended to bait and study human attackers, but honeypots can be used equally well to capture worms. There are three questions related to honeypots:
- How is a honeypot built?
A honeypot should be constructed so that a worm is presented with an environment complete enough to infect. In addition, a honeypot should ideally be impossible for a worm to break out of, and a honeypot should be easy to restore to a pristine state.
Emulators are often considered for honeypot systems, because they meet all these criteria. The major problem with using emulators for honeypots is also a problem when using emulators for anti-virus software: it may be possible for a worm to detect that it is in an emulator.
For example, a worm can look for device names provided by common emulators.
- How is a worm drawn to a honeypot?
A honeypot should be located in an otherwise-unused place in the network, and not be used for any other purpose except as a honeypot. The reasoning is that a honeypot should have no reason to receive legitimate traffic - all traffic to a honeypot is suspicious.
A honeypot doesn't generate network traffic by itself, the downside being that a passive scanning worm will be able to avoid the honeypot. One honeypot with one IP address in an large network stands little chance of being targeted by a worm scanning randomly or quasi-randomly.
A large range of consecutive addresses can be routed to a single honeypot to supply a larger worm target. Other mechanisms can be used to lure the discriminating worm.
A honeypot can provide a fake shared network directory containing goat files, for worms that spread using such shared directories - the goat files and shared directory can be periodically checked for changes that may signify worm activity.
Email worms can be directed to a honeypot by salting mailing lists with fake email addresses residing on the honeypot.
- What can a honeypot do with a worm?
It can capture samples of worms, and be used to gauge the overall amount and type of worm activity. A honeypot is one way to get an early warning of worms. Honeypots can deliberately respond slowly, to try and slow down a worm's spread. This type of honeypot system is called a tarpit.
A worm that scans for infectible machines in parallel will not be susceptible to a tarpit, however. Certain types of worms can be severely impacted by honeypot capture. A hit-list worm passes half its targets along to each newly-infected machine, so hitting a honeypot cuts the worm's spread from that point by half.
It is questionable whether or not honeypots are as useful against worms as other means of defense. Early warning of a spreading worm is useful, but there are other ways to receive a warning, and worm capture is not generally useful to anyone except specialists.
Reverse Firewalls
A reverse firewall filters outgoing traffic from a network, unlike a normal firewall which filters incoming traffic. In practice, filtering in both directions would probably be handled by the same software or device. As with firewalls, the key to an effective reverse firewall is its policy: what outbound connections should be permitted?
The principle is that a worm's connections to infect other machines will not conform to the reverse firewall policy, and the worm's spread is thus blocked. The decision is based on the same packet header information as was used for a firewall, including source and destination IP addresses and ports.
For example, policy may dictate that no machine in the critical network may have an outgoing Internet connection, or that a user's computer may only connect to outside machines on port 80, the usual port for a web server.
A host-based reverse firewall can implement a finer-grained policy by restricting Internet access on a per-application basis. Only certain specified applications are allowed to open network connections, and then only connections in keeping with the reverse firewall's outbound traffic policy.
A worm, as a newly-installed executable unknown to the reverse firewall, could not open network connections to spread. In theory. Still, worm activity is possible in the presence of a host-based reverse firewall:
- A worm can use alternative methods to spread when faced with a reverse firewall, such as placing itself in shared network directories. As a result, no worm code is run on the host being monitored by the reverse firewall.
- Legitimate code that is already approved to access the Internet can be subverted by a worm. A worm can simply fake user input to an existing mail program to spread via email, for instance.
A worm could exhibit viral behavior, too, infecting an existing "approved" executable by indirect means, like a web browser plug-in, or more direct means that a virus would normally use. To guard against the latter case, a host-based reverse firewall can use integrity checking to watch for changes to approved executables.
- Social engineering may be employed by a worm. A host-based reverse firewall may prompt the user with the name of the program attempting to open a network connection, for the user to permit or deny the operation. This would typically happen under two circumstances:
- The program has never opened a network connection before. This would be the case for a worm, newly-installed software, or old, installed software that has never been used.
- The program was approved to use the network before, but has changed; a software upgrade may have occurred, or the program's code may have been infected.
A surreptitious worm could patiently wait until a user installs or upgrades software, then open a network connection. The user is likely to assume the reverse firewall's prompt is related to the legitimate software modification and permit the worm's connection.
The worm may also give its executable an important-sounding name, which the reverse firewall will dutifully report in the user prompt, intimidating the user into allowing the worm's operation for fear that their computer won't work properly.
Legitimate applications may farm out Internet operations to a separate program. Legitimate user prompts from a reverse firewall can request network access approval for software with radically-different names than the application that the user ran.
Users will likely approve any user prompts made shortly after they initiate an action in an application, and a worm can exploit this to sneakily receive a user's approval for its network operations.
The underlying problem with a reverse firewall is that it tries to block unauthorized activity by watching network connection activity, an action performed by worms and legitimate software. False positives are guaranteed, which open the possibility of circumventing the reverse firewall.
Throttling
A reverse firewall can be improved upon by taking context into account. Instead of watching for single connections being opened, the overall rate of new connections can be monitored. A system that limits the rate of outgoing connections that a given machine is allowed to make is called a throttle.
A throttle doesn't attempt to distinguish between worms and legitimate software, nor does it try to prevent worms from entering. It only considers outbound connections, and throttles the rate at which all programs make them.
As a throttle only slows down the connection rate, as opposed to dropping connections, no harm is done even if there are false positives - everything still works, just more slowly.
The throttling process can be refined with more context. Most connections are established to machines that were recently connected to; this is similar to the locality of reference exploited by virtual memory.
For example, a web browser may initially connect to a web site to download a web page, followed by subsequent connections to retrieve images for the page, followed by requests for linked web pages at the site.
A working set of recently-connected machines can be kept for a throttled host. Connections to machines in the working set proceed without delay, as do new connections which fit into the fixed-length working set.
Other connections are delayed by a second, not long enough to cause grief, but effective for slowing down fast-moving worms. Extreme wormlike behavior can be caught with the context provided by the throttling delay. Too many outstanding new connections can cause a machine to be locked out from the network.
TCP connections are started by the connecting machine sending a SYN packet, and a throttle can use these SYN packets as an indicator of new connections. In Figure 1, a pair of machines are throttled with a working set of size two.
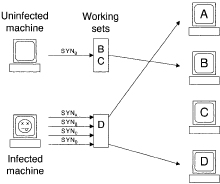
The uninfected machine's new connection to machine B passes through immediately, because B was connected to recently, and is therefore present in the working set.
The infected machine has its connection to machine A go through, because there is one free spot in the working set; machine D is in the working set, and that connection goes through as well.
The other two connections the infected machine makes are delayed. With adaptations, the throttle concept can be extended beyond TCP to UDP, as well as higher-level applications like email and instant messaging.
Throttles are designed around heuristics characterizing "normal" network usage. Like other heuristic systems, throttles can be evaded by avoiding behavior that the heuristics look for.
For example, a worm can slow its rate of spreading down, avoiding the lockout threshold; the number of infection attempts each worm instance makes can be constrained to the throttle's working set size to avoid delays.
Because throttles are not widely used at present, a worm's best strategy may be to ignore the possibility of throttles altogether, as they will not significantly impact the overall worm spread. One criticism leveled at throttles is that they may slow down some programs, like mail transport agents, that can legitimately have a high connection rate.
Different throttling mechanisms which address this criticism can be devised by using additional context information. Worms poking randomly for victims on the network will have a higher probability of failure than legitimate programs - either there is no machine at the address the worm generates, or the machine there doesn't supply a suitably-exploitable service.
A throttle can take the success of connection attempts into account. A credit-based throttle assigns a number of credits to each host it monitors, akin to a bank account. Only hosts with a positive account balance are allowed to make outbound connections; a zero balance will result in a host's outgoing connections being delayed or blocked completely.
A host starts with a small initial balance, and its account is debited for each connection attempt the host makes, and credited for each of the connection attempts that succeed. Host account balances are reexamined every second for fairness: too-high balances are pared back, and hosts with persistent zero balances are credited.
Unfortunately, a credit-based throttle doesn't fare well against worms that violate its assumptions about worm scanning. A worm using hit-list, topological, or passive scanning would naturally tend to make successful connections, for instance. Special attacks can be crafted, too.
A worm need only mix its random scans with connections to hosts (infected or otherwise) that are known to respond, to avoid being throttled. In computer science, sometimes solving the general problem is easier than solving a more specific problem.
Instead of trying to discern worm traffic from legitimate traffic, or watching individual hosts' new connections, a general problem can be considered: how can network load be fairly balanced?
Allocating bandwidth such that high-bandwidth applications (fast-spreading worms, DDoS attacks, file transfers, streaming media) do not starve low-bandwidth applications (web browsing, terminal sessions) may effectively throttle the speed and network impact of worm spread.
Automatic Countermeasures
The losses from worm attacks can be reduced in other ways besides slowing worm propagation. Especially for fast-spreading worms, automatic counter measures are the only possible defense that can react quickly enough. There are two problems to solve:
- How to detect worm activity. Activity detection serves as the trigger for automatic countermeasures.
- What countermeasures to take. The reaction must be appropriate to the threat, keeping in mind that worm detection may produce false positives. Severing the Internet connection every time someone in Marketing gets overzealous surfing the web will not be tolerated for long.
Several methods to detect worm activity have been seen already. Worm capture using honeypots is one method; detecting a sudden spike in excessive throttling is another. Trying to capture various facets of worm behavior leads to other methods, for example:
- A worm may exploit a vulnerability in one particular network server, located at a well-known port. A worm activity monitor can watch for a lot of incoming and outgoing traffic destined to one port.
This can be qualified by the number of distinct IP address destinations, on the premise that legitimate traffic between two machines may involve heavy use of the same port, but worms will try to fan out to many different machines.
- Most network applications refer to other machines using human-readable domain names, which are mapped into IP addresses with queries to the domain name system (DNS). Worms, on the other hand, mostly scan using IP addresses directly.
Worm activity may thus be characterized by correlating DNS queries with connection attempts - connections not preceded by DNS requests may signify worms." Unfortunately, this registers false positives for some legitimate applications, so a Draconian reaction based on this classifier is not the best idea.
What reaction should be taken to worm activity? Some examples of automatic countermeasures are below.
- Affected machines can be cut off from the network to prevent further worm spread. A more aggressive approach may be taken to guard critical networks, which may be automatically isolated to try and prevent a worm from getting inside them.
- Targeted network servers can be automatically shut down.
- Filtering rules can be inserted automatically into firewalls to block the hosts from which worm activity is originating. Or, a filter can drop packets addressed to the port of a targeted network server, which is less resourceintensive as the number of worm-infected machines increases.
Automatic countermeasures must be deployed judiciously, because an attacker can also use them, deliberately triggering the countermeasures to perform a DoS attack. This danger can be mitigated by providing automatic countermeasure systems with a whitelist, a list of systems which are not allowed to be blocked

